In the vision of SAP, HANA can be installed at several levels:
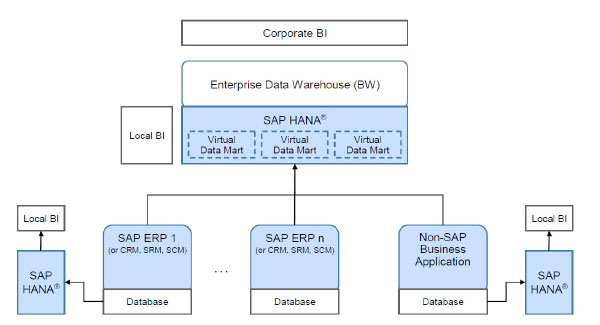
SAP HANA in a data mart side-car approach
SAP HANA sits beside one SAP system (CRM, SRM, SCM, …) and, via replication, it receives an extract of the data from this system. It can then be used by a local BI.
SAP HANA as a database for SAP NetWeaver BW
The BW database at corporate level can be replaced by an SAP HANA appliance. This means that the whole corporate database will be loaded in-memory.
SAP HANA with third-party software
The openness of SAP HANA allows it to receive replicated data from third-party non-SAP applications.
Implementation of Big Data ready Real-time Data Platform with Hadoop
In the vision of SAP, HANA can be installed at several levels:
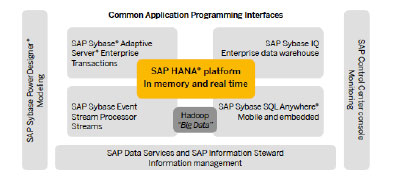
Apache Hadoop open source software enables massively parallel analytical processing distributed on clusters of inexpensive servers. In particular, it allows low cost treatment of very large volumes of structured and unstructured data, in text, audio or video formats. But Hadoop is a batch-oriented system that is not per se friendly to real-time requirements. However, a very interesting solution for "big data" can be obtained by combining the ability of Hadoop to analyse huge amounts of data with SAP HANA’s capabilities in real-time transactional processing.